Pełzając po stronie
Wykorzystanie pamięci podręcznej potrafi drastycznie zredukować czas ładowania dynamicznych stron internetowych. Dzieje się tak jednak tylko w momencie, kiedy pamięć podręczna jest wygenerowana i świeża (tzn. jej czas życia jest aktualny, a pliki mogą zostać wysłane do przeglądarki użytkownika).
Często aktualizowane strony, strony oparte o dużą liczbę zmiennych, albo np. systemy e-commerce nie mogą korzystać z długiego czasu życia pamięci podręcznej, co zwiększa prawdopodobieństwo, że odwiedzający nie trafią na przygotowaną wcześniej stronę i będą musieli zaczekać na jej wygenerowanie.
Popularnym rozwiązaniem tego problemu jest uruchomienie robota indeksującego, który na podstawie dostępnej mapy strony, cyklicznie odświeża pamięć cache, bez udziału użytkowników. Dzięki pracy robota, odwiedzający stronę znacznie częściej trafią na świeżą pamięć podręczną, co wpłynie pozytywnie na ich interakcję z naszym serwisem, oraz zmniejszy prawdopodobieństwo porzucenia strony (w wyniku zbyt długiego czasu oczekiwania na jej załadowanie).
LiteSpeed Cache, dostępny dla użytkowników CMS WordPress korzystających z serwerów LiteSpeed oferuje funkcjonalność robota indeksującego. Niestety zagadnienia natury user experience, toporny interfejs wtyczki oraz wykorzystanie kiepskiego tłumaczenia maszynowego w polskiej wersji wtyczki sprawiają, że poprawna konfiguracja robota nie należy do najbardziej oczywistych czynności.
Przy okazji wdrożenia, nad którym obecnie pracuję, przyjrzałem się zagadnieniom crawlera nieco dokładniej.
Niniejszy artykuł zawiera opis działania robota indeksującego we wtyczce LiteSpeed Cache dla WordPress w wersji 3.6.1 oraz propozycję jego konfiguracji dla hostingu EWH w dhosting. Artykuł nie wyczerpuje zagadnienia — nie zgłębiam się np. w tworzenie osobnych robotów indeksujących dla ról użytkowników lub symulacji ciasteczek.
Jeśli nie wiesz, czym jest LiteSpeed Cache i jakie funkcjonalności oferuje, zapraszam najpierw do przeczytania poprzednich artykułów na ten temat:
Najlepsza wtyczka cache dla WordPress
Skuteczna optymalizacja grafik w WordPress dzięki wtyczce LiteSpeed Cache
Większa wydajność stron internetowych dzięki implementacji ESI w LiteSpeed Cache
Możesz także śledzić tag LiteSpeed Cache dla WordPress na moim blogu, gdzie pojawiają się wpisy związane z tą wtyczką.
Jak działa crawler (robot indeksujący) w LiteSpeed Cache?
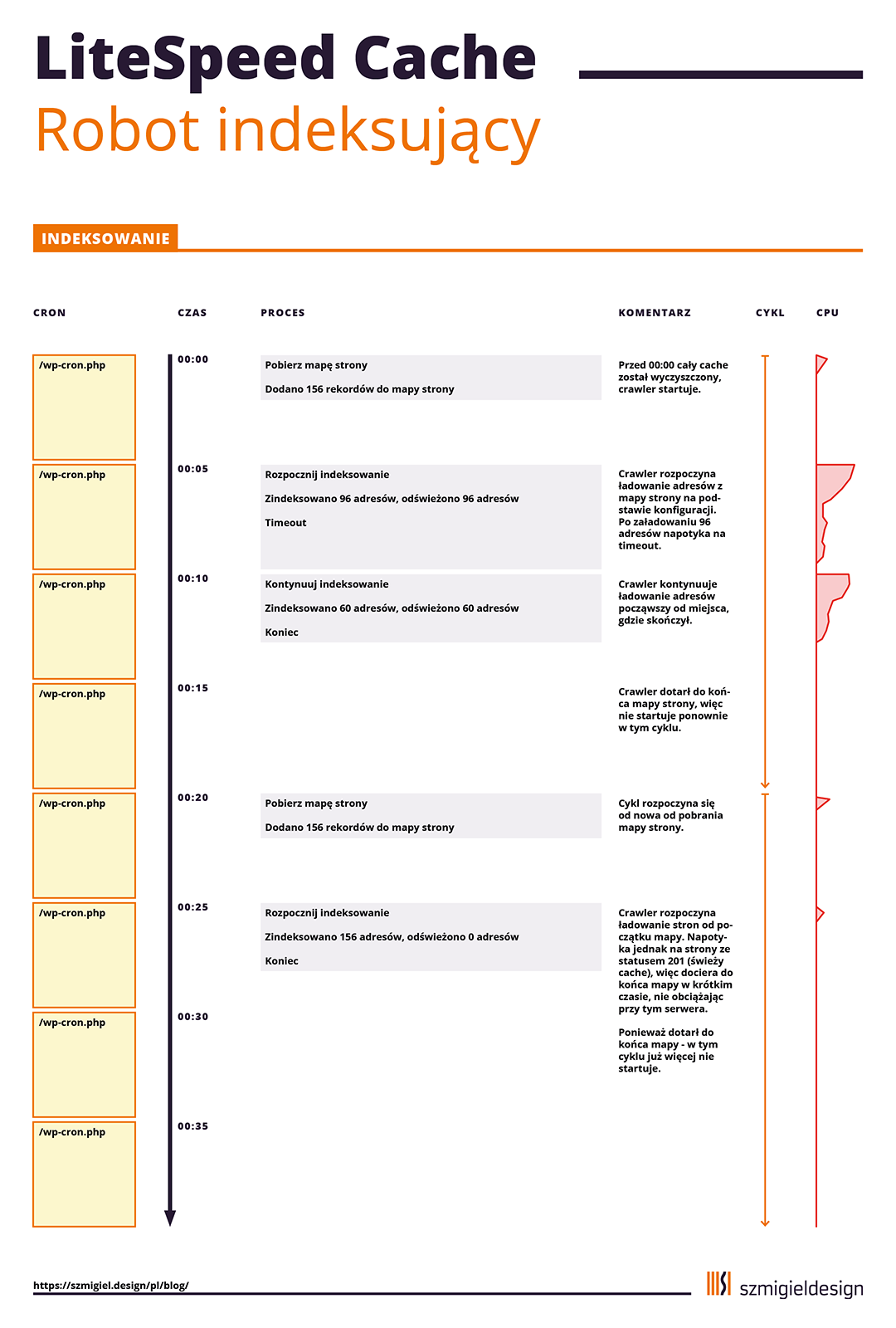
Crawler działa powtarzalnie i jest wywoływany przez cron — wbudowany w WordPress i uruchamiany przez wejście na stronę lub przez wywołanie pliku wp-cron.php.
Kompletny cykl działania robota indeksującego liczony jest od zindeksowania mapy strony (sitemap) do zakończenia generowania cache dla każdego rekordu dostępnego w ramach mapy (robot symuluje otwarcie każdej strony z mapy i tym samym wymusza wygenerowanie cache).
Proces można streścić w kilku punktach:
- Pobierz i przetwórz mapę strony, zapisując w bazie wszystkie adresy do załadowania i wygenerowania pamięci podręcznej.
- Uruchom proces robota na czas ustawiony w konfiguracji i rozpocznij ładowanie każdego adresu, po kolei aż do dotarcia do ostatniego adresu lub do wyczerpania czasu.
- Zrób przerwę w indeksowaniu na czas ustawiony w konfiguracji.
- Jeżeli w punkcie 2 robot nie dotarł do końca mapy strony, kontynuuj ładowanie adresów z mapy, rozpoczynając od miejsca, na którym skończył się punkt 2. Jeżeli robot dotarł do końca mapy strony, zatrzymaj robota do czasu następnego indeksowania mapy stron (rozpoczęcia cyklu).
Przy czym punkty 2 i 3 pracują w pętli do czasu dotarcia do ostatniego adresu z mapy strony lub — jeżeli nastąpi szybciej — do następnego ponownego uruchomienia cyklu (dlatego ważne jest wykonanie testów i ustawienie czasu cyklu na dłuższy niż trwa odświeżenie pamięci podręcznej dla wszystkich adresów strony).
Wymagania techniczne niezbędne do uruchomienia crawlera
Do uruchomienia robota indeksującego nie wystarczy jedynie hosting oparty o serwer LiteSpeed. Oprócz tego funkcjonalność robota nie może być wyłączona administracyjnie (jeżeli tak się stanie, na stronie podsumowania zobaczysz taką informację).
Co równie ważne, a czego nie dowiesz się z komunikatów o błędzie wyświetlanych na stronach wtyczki, WordPress musi mieć dostęp do funkcji PHP sys_getloadavg. Funkcja ta zwraca wtyczce informację o aktualnym obciążeniu konta hostingowego (serwera) i umożliwia spowolnianie robota indeksującego tak, aby nie zmonopolizował wszystkich zasobów.
To ważne, ponieważ niektóre hostingi (w tym polecany przeze mnie dhosting) domyślnie uniemożliwiają wywołanie tej funkcji.
Doprowadza to do kuriozalnej sytuacji, w której robot, mimo poprawnej konfiguracji i braku zwracanych błędów, nie działa. W kodzie wtyczki w wersji 3.6.1 znajduje się warunek, który sprawdza, czy funkcja jest dostępna, ale jeżeli nie jest — po prostu wyłącza działanie robota bez informowania o tym w żaden sposób użytkownika.
Jeżeli więc na stronie podsumowania, mimo konfiguracji robota i jego manualnego włączenia, nie pojawiają się informacje o wielkości mapy strony — sprawdzenie czy funkcja sys_getloadavg jest dostępna, będzie dobrym tropem podczas próby ustalenia, dlaczego robot nie działa. Przy okazji podziękowania dla Damiana Ślimaka za odkrycie źródła tego problemu.
Status robota (robotów) indeksujących
Za konfigurację robota indeksującego w LSCWP (LiteSpeed Cache for WordPress) odpowiada dedykowana zakładka wtyczki pn. „Robot indeksujący” i dalsza część artykułu dotyczy informacji zawartych w kilku sekcjach tej zakładki.
Po przejściu na główną sekcję — Podsumowanie — zobaczymy ogólne informacje dotyczące stanu indeksowania oraz zadania cyklicznego (cron) robota.
Jedna z pierwszych rzeczy, które rzucają się w oczy to wątpliwej jakości tłumaczenie, które dodatkowo komplikuje zrozumienie, jak działa robot.
Pozwolę sobie zatem przetłumaczyć frazy na ich faktyczne znaczenie:
Aktualny robot indeksujący mapę strony wystartował w
To czas (względny), kiedy po raz ostatni mapa strony (sitemap) została przez LSCWP załadowana i zapisana w bazie danych w celu jej wykorzystania przez robota.
Następne kompletne indeksowanie mapy witryny rozpocznie się za
To czas (bezwzględny), na kiedy zaplanowane jest kolejne indeksowanie mapy strony. Innymi słowy — kiedy po raz kolejny proces indeksowania strony rozpocznie się od nowa.
Ostatnie pełne uruchomienie wszystkich robotów indeksujących
Ile czasu zajęło wszystkim robotom indeksującym (bo może ich być więcej niż jeden) odpytanie każdego rekordu widocznego w mapie strony (załadowanej podczas startu cyklu robota).
Ostatni czas uruchomienia robota indeksującego
Jak długo pracował robot indeksujący podczas ostatniego wywołania. Nie dotyczy to całego cyklu indeksowania liczonego od początku indeksowania mapy strony do odpytania ostatniego rekordu, ale pojedynczego uruchomienia robota w cyklu, czyli jego procesu (o tym dalej).
Aktualny robot indeksujący wystartował w
Wprawdzie robotów indeksujących może być kilka, ale jednocześnie może działać tylko jeden. Ta informacja dotyczy aktualnego robota indeksującego, czyli tego, który obecnie indeksuje stronę, lub… Skończył ją indeksować, ale nowy jeszcze nie wystartował.
Praktyczna konfiguracja robota indeksującego
1. Dodajemy mapę strony
Na początek przechodzimy do sekcji — Ustawienia Mapy Strony — i wklejamy tam adres do mapy strony w formacie XML.
Skąd ją wziąć? Począwszy od WordPress 5.5, generowana jest automatycznie i powinna być dostępna pod głównym adresem strony z dopiskiem /wp-sitemap.xml.
Mapa strony może być również wygenerowana przez jedną z wielu wtyczek SEO dla WordPress, np. Yoast SEO lub SEOPress z którego sam korzystam i polecam.
Opcja Drop Domain from Sitemap sprawia, że mapa strony zostanie przetworzona z wykluczeniem domeny. Jeżeli korzystamy z kilku domen lub np. nietypowej konfiguracji WPML, należy wyłączyć tę opcję, aby robot poprawnie zinterpretował mapę strony i załadował wszystkie adresy.
Czas mapy strony, czyli limit czasu przeznaczony na wczytanie i przetworzenie mapy strony. Nie powinien być zbyt krótki, aby upewnić się, że wszystkie adresy zostały załadowane. Domyślna wartość 120 sekund wydaje się optymalna.
2. Włączamy robota
Przechodzimy do sekcji — General Settings — gdzie znajdziemy większość ustawień robota.
Idąc od góry — włączamy robota indeksującego.
3. Ustalamy opóźnienie
Opóźnienie oznacza odstęp czasu, wyrażony w mikrosekundach, pomiędzy ładowaniem kolejnych adresów z mapy strony.
Odpowiednie ustawienie opóźnienia jest istotne, ponieważ ma wpływ na całkowity czas ładowania wszystkich adresów, a tym samym czas pracy robota indeksującego.
Opóźnienie ma również wpływ na obciążenie serwera. Przykładowo, jeżeli korzystasz z EWH w dhosting, ale nie chcesz, aby robot uruchamiał skalowanie, ustaw opóźnienie na nieco większą wartość, np. 10000. Spowoduje to, że kolejne adresy z mapy strony będą ładowane przez robota w odstępach co 0.01 sekundy.
Warto poeksperymentować z wartościami w zakresie 10000 do 30000.
4. Ustalamy czas uruchomienia (proces, pętla)
Czas uruchomienia to czas, przez który będzie uruchomiony proces robota indeksującego, czyli jak długo robot będzie wykonywał swoją pracę. Wartość ta uzależniona jest od parametru serwera max_execution_time oraz limitu czasu cron (jeżeli korzystamy z crontab zamiast crona wywoływanego przez WordPress).
Możesz pozostawić wartość domyślną (400), albo ustawić identyczną z max_execution_time. W najgorszym wypadku — proces robota indeksującego zostanie zakończony przez limit czasu, ale wystartuje ponownie.
5. Ustalamy czas bezczynności (proces, pętla)
Interwał między uruchomieniami to czas bezczynności pomiędzy kolejnymi uruchomieniami robota ustalonymi w punkcie 4.
Po co czas bezczynności? W przypadku dużych stron, limity serwera mogą uniemożliwić robotowi załadowanie wszystkich adresów z mapy strony w ustalonym limicie czasu i tym samym wygenerowanie pamięci podręcznej dla wszystkich stron. Dzięki cyklicznemu uruchamianiu może on wykonać swoją pracę mając do dyspozycji mniejsze zasoby.
Można to zrozumieć tak, że proces robota indeksującego i czas bezczynności uruchamiane są w pętli do czasu, aż indeksowanie zostanie zakończone (albo zresetowane w wyniku uruchomienia go ponownie).
Proponuję, aby czas bezczynności ustawiać w zakresie pomiędzy 1 a 5 minut (300 sekund).
6. Ustalamy, jak często uruchamiać robota (cały cykl)
Interwał robota indeksującego, czyli jak często uruchamiać cały cykl od początku do końca (pobranie mapy strony, załadowanie wszystkich adresów i wygenerowanie dla nich pamięci podręcznej).
To prawdopodobnie najważniejszy element konfiguracji robota i powinien być ściśle uzależniony od charakteru strony, z jaką mamy do czynienia.
Dla stron zawierających wiele treści dynamicznych i z krótkim czasem życia (TTL) pamięci podręcznej, wartość tego pola powinna być o wiele mniejsza, niż proponowana domyślnie, np. 1800, czyli pół godziny.
Dla stron nie wymagających tak częstego odświeżania pamięci podręcznej wystarczą 3 godziny, albo nawet rzadziej.
Jednak domyślna wartość jest wg mnie bezużyteczna i dla stron, których mapa strony zawiera poniżej 200 rekordów, z powodzeniem można rozpocząć testy z wartością 3600 sekund, czyli pełnej godziny.
Pamiętaj, że sam fakt ponownego uruchomienia cyklu robota indeksującego nie musi być obciążający dla serwera. Robot uruchomi się zgodnie z zaprogramowanym interwałem, ale jeżeli napotka na świeży cache, nie wymusi jego ponownego wygenerowania, a cały proces może skończyć się nawet w kilka sekund.
To nie działanie robota jest obciążające dla serwera, ale generowanie pamięci podręcznej z treści dynamicznych, które uruchamia. Robot robi to samo, co dowolna osoba odwiedzająca stronę, ale automatycznie.
7. Określamy liczbę wątków
Wątki określają liczbę adresów z mapy strony ładowanych jednocześnie. Ten parametr, podobnie jak Opóźnienie, ma wpływ na szybkość, z jaką robot załaduje wszystkie strony z mapy, ale także, jakie będzie początkowe obciążenie serwera — więcej o tym w punkcie 9.
Domyślna wartość może skutkować krótkim skokiem (spike) wykorzystania zasobów serwera. Jeżeli nie zależy Ci na szybkim odświeżeniu pamięci podręcznej przez robota, ale raczej jego niezawodnym i niezauważalnym działaniem w tle — sugeruję rozpoczęcie testów z tylko jednym wątkiem i stosunkowo wysokim opóźnieniem.
8. Ustalamy maksymalny czas ładowania jednego adresu
Timeout, czyli jak długo robot będzie oczekiwał na załadowanie adresu, zanim przejdzie do następnego. Domyślna wartość jest ok i jeżeli potrzebujesz ją wydłużyć to w pierwszej kolejności powinieneś ustalić, dlaczego czas generowania Twoich stron jest tak długi.
9. Określamy limit obciążenia serwera
Limit obciążenia serwera, czyli ile zasobów serwera może wykorzystać robot indeksujący podczas działania procesu.
Podana tutaj wartość bezpośrednio odnosi się do funcji PHP sys_getloadavg.
W przypadku EWH w dhosting wartość 1 w przybliżeniu oznacza 1 GHz, 10 odpowiednio 10 GHz, 16 to 16 GHz, etc. Ciężko jednoznacznie określić, jak wartości zwracane przez funkcję mają się do obciążenia serwera — warto dopytać o to administratorów, jeżeli hosting umożliwia wykorzystanie crawlera.
Istotne jest zrozumienie, że limit obciążenia serwera nie jest nieprzekraczalną ścianą i ustalenie wartości na 1 uchroni nas np. przed uruchomieniem elastycznego skalowania w dhosting.
Robot indeksujący wywołuje jednoczesne ładowanie tylu adresów z mapy strony, ile jest wątków. Dopiero po ich kompletnym załadowaniu oraz odczekaniu czasu podanego w polu „Opóźnienie”, przed załadowaniem kolejnych adresów, sprawdza wartość funkcji sys_getloadavg.
Jeżeli wartość zwracana przez funkcję jest większa niż ustalony limit, robot zmniejszy liczbę wątków o jeden i będzie kontynuował swoją pracę.
Hipotetycznie, jeżeli ustalisz liczbę wątków na 16, ale limit obciążenia na 1, zanim robot ograniczy liczbę wątków do 1, zdąży załadować 135 adresów, przez cały ten czas korzystając z zasobów serwera (16 + 15 + 14 + 13 + (…) + 3 + 2 + 1 + 1 + 1 + 1 aż do końca mapy).
Dlatego konfigurację robota indeksującego warto rozpoczynać od wartości bezpiecznych — zwiększając je w razie potrzeby, ale nie odwrotnie.
1 to dobry start, ale w razie potrzeby można użyć też niższych wartości, np. 0.8. Przy czym należy pamiętać, że jeżeli robot osiągnie 1 wątek i nie będzie w stanie utrzymać obciążenia serwera poniżej limitu — zakończy proces (przy następnym uruchomieniu spróbuje ponownie od miejsca, gdzie zakończył swoją pracę).
Jeżeli chcesz, aby indeksowanie przebiegało szybko i często i masz dostęp do wysokich zasobów serwera, możesz ustawić wątki i limit na 16.
Testowanie robota indeksującego
Po zakończeniu konfiguracji robota warto wykonać kilka manualnych testów w celu sprawdzenia obciążenia serwera oraz założeń, które przyjęliśmy podczas konfiguracji.
W tym celu, po zapisaniu danych formularza, przechodzimy do zakładki — Podsumowanie — następnie z paska administracyjnego na górze ekranu odnajdujemy logo LiteSpeed i z menu wybieramy „Opróżnij wszystko”.
Możemy teraz kliknąć przycisk „Ręczne uruchomienie”.
Pierwsze uruchomienie powinno spowodować wczytanie mapy strony i wypełnienie szarych pól w kolumnie „Stan” tabeli widocznej na stronie podsumowania.
Kolejne kliknięcie „Ręczne uruchomienie” spowoduje uruchomienie procesu zgodnie z konfiguracją robota na czas ustalony w polu „Czas uruchomienia”.
Strona zaplecza będzie oczekiwać na odpowiedź serwera tak długo, jak długo pracuje robot indeksujący, albo do osiągnięcia limitu czasu. Jeżeli strona zwróci błąd (timeout), po prostu załaduj ją ponownie. Teraz, w kolumnie „Stan” tabeli powinieneś zobaczyć wypełnione niebieskie i zielone pola, co świadczy, że robot wykonał przynajmniej część swojej pracy.
Zielone pola oznaczają liczbę adresów z mapy strony, dla których robot napotkał świeży cache. Niebieskie natomiast oznaczają adresy, dla których TTL minął albo nieposiadające cache (np. w wyniku aktualizacji treści lub wyczyszczenia całej pamięci podręcznej). Kolorem czerwonym oznaczone są adresy, które trafiły na czarną listę (np. w wyniku przekroczenia dozwolonego czasu ładowania).
Kolejne kliknięcie „Ręczne uruchomienie” spowoduje albo ponowne załadowanie mapy strony i rozpocznie proces od nowa (jeżeli robot zakończył swoje działanie w wyniku tylko jednego uruchomienia), albo spowoduje kontynuowanie ładowania adresów z mapy strony w miejscu, gdzie robot zakończył ostatni proces.
Na podstawie testu, możesz określić, czy wprowadzone w konfiguracji wartości są poprawne, czy wymagają aktualizacji.
Jeżeli masz dostęp do takich danych — warto sprawdzić obciążenie serwera.
Jeżeli robot został uruchomiony przez cron — możesz podejrzeć jego bieżące poczynania korzystając z konsoli widocznej pod tabelą, klikając w przycisk „Wyświetl stan robota”.
Włączenie zadania cyklicznego (cron) niezależnego od WordPress
Wprawdzie WordPress posiada wbudowany system planowania zadań, ale ich uruchomienie wymaga załadowania dowolnej strony w serwisie. Jeżeli więc nikt nie wchodzi na naszą stronę — zaplanowane zadania nie zostaną uruchomione na czas.
Rozwiązaniem tego problemu jest zaprogramowanie zadania cyklicznego uruchamianego przez serwer (hosting).
W tym celu możesz skorzystać z panelu hostingu, usługi SSH, albo poprosić o pomoc administratorów. W przypadku WordPress, wystarczy za pomocą programu wget wywoływać adres /wp-cron.php w folderze głównym Twojej strony internetowej, np. co 5 lub co 10 minut.
Warto przy tym pamiętać o kilku rzeczach:
- Cron nie powinien działać częściej niż limit czasu dla crona. Przykładowo, jeżeli cron jest uruchamiany co 5 minut, nie powinien działać dłużej niż 5 minut (timeout).
- Jeżeli cron startuje co 5 minut, warto wykorzystać ten interwał przy konfiguracji robota indeksującego. Zarówno „czas uruchomienia”, jak i „interwał między uruchomieniami” mogą wynosić 5 minut — lub wielokrotność 5 minut.
- Również parametr “interwał robota indeksującego” może być wielokrotnością czasu, z jakim startuje cron. Dzięki temu żadne zadanie nie zostanie uruchomione z opóźnieniem wynikającym z „rozminięcia się” startu cron oraz czasem zaplanowanych zadań.
Robot indeksujący — graficzny schemat działania
Podsumowanie
Wykorzystanie szybkiej pamięci podręcznej w przypadku rozbudowanych stron internetowych opartych o systemy zarządzania treścią to dobry i relatywnie tani sposób na zwiększenie komfortu interakcji ze stroną.
Pamięć podręczna jest jednak przydatna tylko wtedy, kiedy jest dostępna. Automatyczne aktualizacje WordPress i wtyczek, zmieniające się stany produktów lub komentarze dodawane do artykułów – wszystkie te rzeczy mogą wymusić unieważnienie pamięci podręcznej, sprawiając, że kolejna osoba odwiedzająca daną stronę będzie czekać znacznie dłużej na jej wyświetlenie.
Jeżeli pozwala na to serwer, warto uruchomić robota indeksującego i tym samym jak najczęściej serwować użytkownikom zawartość stron internetowych z szybkiej pamięci podręcznej serwera LiteSpeed.


{kind=link}
{kind=link}